Part 2: One Coordinator, Swappable Coding Engines
In the last post I described an always-on agent that plans work, delegates the implementation, and reviews the result before calling it done. The split is the whole point: the coordinator never writes code, and the thing that writes code never plans.
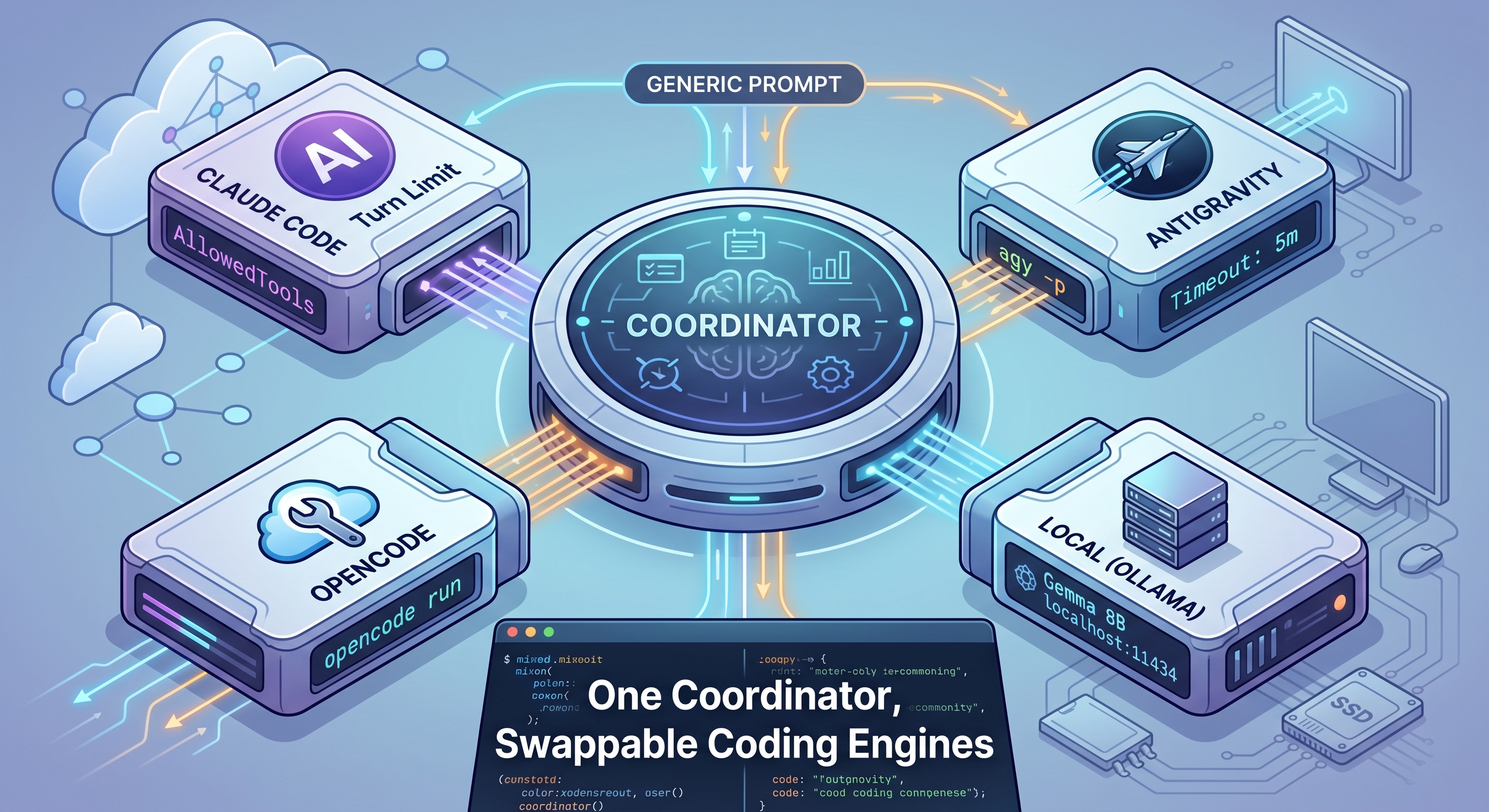
But I left one detail underspecified. In that setup, the thing that writes code was Claude Code. One coordinator, one implementer, hard-wired together.
Coding engines change. New ones show up every few months, old ones shift their flags, pricing moves, a model gets deprecated out from under you. If your coordinator only knows how to talk to one of them, every one of those changes is a rewrite. And you lose the ability to do the obvious thing: run a cheap engine on cheap work and an expensive one on hard work.
So I pulled the implementer out into its own layer. The coordinator no longer dispatches to “Claude Code.” It dispatches to a harness, and the harness is swappable. Today I have implemented four of them, including one that runs entirely on my own machine.
What a harness actually is
A harness is a thin contract: take a self-contained prompt, run it non-interactively against a coding engine in a project directory, and return the result. No chat session, no back-and-forth. One shot.
Every engine I use already supports this mode, because it’s how you’d script them anyway:
- Antigravity:
agy -p '<prompt>' - Claude Code:
claude -p '<prompt>' - OpenCode:
opencode run '<prompt>'
The flags differ, the auth differs, the strengths differ. But the shape is identical: prompt in, work done, result out. That shared shape is what makes the engine swappable. The coordinator builds a prompt the same way regardless of which engine will run it; only the command wrapper changes at the end.
That’s worth sitting with, because it’s the part that makes the rest possible. The coordinator’s job — turning a plan into a precise, self-contained instruction — does not depend on which engine executes it. A good dispatch prompt names the files, describes the change, points at an example to follow, and says how to verify. That prompt is just as good whether Antigravity or a local model picks it up. The plan does the thinking. The harness does the typing.
The dispatch templates are the same; the wrapper changes
I dispatch the same handful of task shapes over and over: implement a feature, edit one file, fix a bug, refactor a component, review a diff, run a targeted fix loop. Each shape is a template — what context to include, what to ask for, how to tell the engine it’s done.
Those templates live above the harness layer. When the coordinator decides to dispatch a bug fix, it fills in the bug-fix template — reproduce with these steps, root cause is likely here, add a regression test — and only then wraps it in whichever engine’s command syntax is active:
# Antigravity
agy -p '<bug-fix prompt>' --dangerously-skip-permissions --print-timeout 5m0s --add-dir <project>
# Claude Code
claude -p '<bug-fix prompt>' --dangerously-skip-permissions --allowedTools 'ReadFile,EditFile,Bash' --max-turns 15
# OpenCode
opencode run '<bug-fix prompt>' --dir <project> --dangerously-skip-permissions -m google-vertex/gemini-3.5-flash
Same prompt, three wrappers. Add a fourth engine and you write one more wrapper, not a new set of templates.
The cloud engines
Three of the four harnesses are cloud-backed, and they’re not interchangeable. Each is good at something the others aren’t.
All three need auth set up before they’ll run. The easiest way is to do it interactively on the machine — run each CLI once, walk through its login flow, and let it cache the credentials. Claude Code and OpenCode can both be authenticated headlessly (API keys, service accounts, environment variables), which matters if you’re setting this up on a remote box or in CI. Antigravity, as of this writing, cannot — its OAuth flow requires an interactive browser session to complete. If you’re planning to run agy on a headless server, that’s worth knowing up front.
Antigravity (agy) is the simplest to drive. It has a built-in print-mode timeout (--print-timeout 5m0s, in Go duration format), and a --sandbox flag that restricts terminal access for read-only review work. What it doesn’t have is a tool allowlist or a turn limit — a task runs until it finishes or the timeout fires. It’s a good fit when the job is well-scoped and I’d rather lean on a hard time budget than fiddle with per-tool permissions.
Claude Code has the finest-grained controls. --allowedTools lets me restrict exactly which tools a task can touch, so a code review runs read-only and an implementation gets write access — per dispatch, not globally. --max-turns caps how many iterations a task can take before it stops, which keeps a runaway refactor from grinding forever. And --append-system-prompt lets me inject stack-specific guidance without rewriting the user prompt. When I care most about output quality and control, this is the one I reach for.
OpenCode is the most flexible about models. It takes a model override per invocation (-m), a reasoning-effort dial (--variant high), structured JSON output (--format json), and file attachments (-f). The model flexibility is the headline feature, and it’s exactly what makes the fourth harness possible.
A local model is just another harness
Here’s the part I didn’t have working when I wrote the first post.
OpenCode accepts a custom OpenAI-compatible endpoint. Ollama — the thing I use to run open-weight models locally — exposes exactly that endpoint, at http://localhost:11434/v1, the moment it’s installed. Point one at the other and the local model becomes a coding harness through the same dispatch path as everything else:
opencode run '<prompt>' --dir <project> --dangerously-skip-permissions -m openai/gemma4:latest --api-base http://localhost:11434/v1
Nothing else in the stack changes. The coordinator builds the same prompt, fills in the same template, and wraps it in the same opencode run command. The only difference is that the model answering lives on my SSD instead of in a datacenter. No tokens billed, no code leaving the machine, no network required.
I want to be honest about the trade-off, because it’s real running on an older Intel model Mac with 32GB of memory. The model I’m running locally today is an 8-billion-parameter Gemma. That’s a small model by current standards, and I’ve calibrated it accordingly: it gets the small, scoped, repetitive work — a single-file edit, a batch of boilerplate tests, a formatting pass — and the cloud engines get anything that needs deep reasoning across many files. An 8B model is not going to architect your auth system.
But “small model, small tasks” is a hardware statement, not a ceiling. The whole reason Apple Silicon matters here is unified memory: the GPU reads system RAM at enormous bandwidth, so a Mac with enough memory can run models that would need a dedicated GPU anywhere else. Move to a machine with 32GB or more and the same harness slot takes a 26B-class Gemma or a 30B Qwen coder — models that hold their own against the mid-tier cloud options on real programming work. The interface doesn’t change. You swap the model string and the local harness quietly gets a lot more capable.
The same local model does double duty, too. Outside of coding dispatches, it runs the unglamorous support work that would otherwise burn cloud tokens all day: classifying backlog items, summarizing what went wrong after a failed build, stripping AI tells out of commit messages. That work is constant and low-stakes — perfect for a model that’s free and already running. The coding-harness role is the newer, more interesting one, but it’s the same engine underneath.
How I swap between harnesses
The config sets a default engine — coding.default_engine: agy — and that’s what the coordinator uses unless I tell it otherwise. Most sessions run start to finish on the default, and that’s fine. A good dispatch prompt is engine-agnostic; the plan carries the quality, not the engine.
But the whole point of a swappable layer is that you can swap it. Mid-session, I can tell Hermes “use claude” and the next dispatch goes through Claude Code. “Use opencode with ollama” points it at the local model through OpenCode’s endpoint override. The coordinator rebuilds the wrapper; the templates and the prompt stay the same. When I’m done with the detour, “use agy” puts it back.
That flexibility matters most when different parts of a session call for different strengths. A quick single-file fix might not need a cloud round-trip — the local model handles it and I save the tokens. A complex multi-file refactor gets Claude Code’s tool allowlist and turn limits. Swapping is one sentence, not a config change.
The place I’m headed next is splitting engines by role, not just by task. Right now, whatever harness is active does both the implementation and the review. But there’s no reason the same model has to do both. Write the code with one engine, review the diff with a different one — different models, different blind spots. A bug that one model introduced is exactly the kind of thing a second model is more likely to catch, because it doesn’t share the same reasoning path that produced the bug in the first place. I haven’t wired this up yet, but the layer already supports it. The coordinator dispatches to a harness; nothing says the implementation dispatch and the review dispatch have to use the same one.
What this buys me
Pulling the engine out into a swappable layer changed the system in a few concrete ways.
It’s resilient to churn. When an engine changes its flags or a model gets deprecated, I edit one wrapper. The templates, the plans, the review flow — all untouched.
It’s cheaper by default. Cheap, repetitive work goes to a model that costs nothing and runs locally. Cloud tokens get spent on the work that actually needs them.
It has a private mode. When the code shouldn’t leave the machine, the local harness handles it end to end — no network, no third party.
And it’s future-proof in the only way that matters: when the next coding engine ships, adding it is a wrapper and a row in a flags table, not a redesign.
The local harness is the piece I’m happiest with, because it turns “use a local model” from a separate, special-cased integration into just another row in that table. Same interface, different address.
What’s next
Right now, every harness dispatch gets the same context: a self-contained prompt and whatever local skills the coordinator already knows about. The next post is about making that context dynamic — discovering the specific knowledge a task needs from external sources and injecting it into the harness at dispatch time, so the agent gets exactly the right tools and nothing it doesn’t need.
The Hermes Agent series
- Part 1: I Built an Always-On AI Coding Agent That Plans, Codes, and Reviews Its Own Work
- Part 2: One Coordinator, Swappable Coding Engines (this post)
- Part 3: Dynamic Tool Discovery and Injection
- Part 4: Running Untrusted Tools Safely
- Part 5: GitHub Issues as the Agent’s Backlog
- Part 6: The Autonomy Ladder
- Part 7: How the Agent Learns From Its Mistakes