Part 3: Dynamic Tool Discovery and Injection
There’s a scene in The Matrix where Neo sits down, a program uploads directly into his brain, and ten seconds later he opens his eyes and says: “I know Kung Fu.” No training, no practice. The skill just appears, fully formed, exactly when he needs it.
That’s what I wanted the coordinator to do with tools.
In the last post I described how the coordinator dispatches work to swappable coding engines. Every dispatch gets the same treatment: a self-contained prompt, wrapped in whichever harness is active, with a fixed set of tools. That last part – “fixed set of tools” – is the constraint this post removes.
The context problem
A coding agent works best when it knows exactly what it needs and nothing else.
That sounds obvious, but it’s the opposite of what most setups do. The default approach is to front-load everything: paste in all the project documentation, all the style guides, all the API references, and let the model sort out what’s relevant. It works for simple tasks. It falls apart for complex ones, because the model spends its attention budget parsing context it doesn’t need instead of reasoning about the problem it does.
The insight that changed how I build dispatches is that a good prompt isn’t just a task description. It’s three things:
- A role – what the agent is and isn’t allowed to do. The coordinator/implementer split from the first post: the harness writes code, it doesn’t plan.
- A task – a self-contained instruction. Name the files, describe the change, say how to verify.
- Knowledge – the specific context this task needs to succeed. Not “everything about the project,” but “the Firestore client library patterns, the existing test conventions for this module, and the schema for this collection.”
The first two are straightforward. The third one is the hard part, because the right knowledge changes with every task. A task that touches Firestore needs different context than one that writes a Terraform template. If the coordinator injects the same blob of context into every dispatch, most of it is noise – and noise costs you. It dilutes the model’s attention, it burns tokens, and in the worst case it actively misleads the agent by surfacing patterns from the wrong domain.
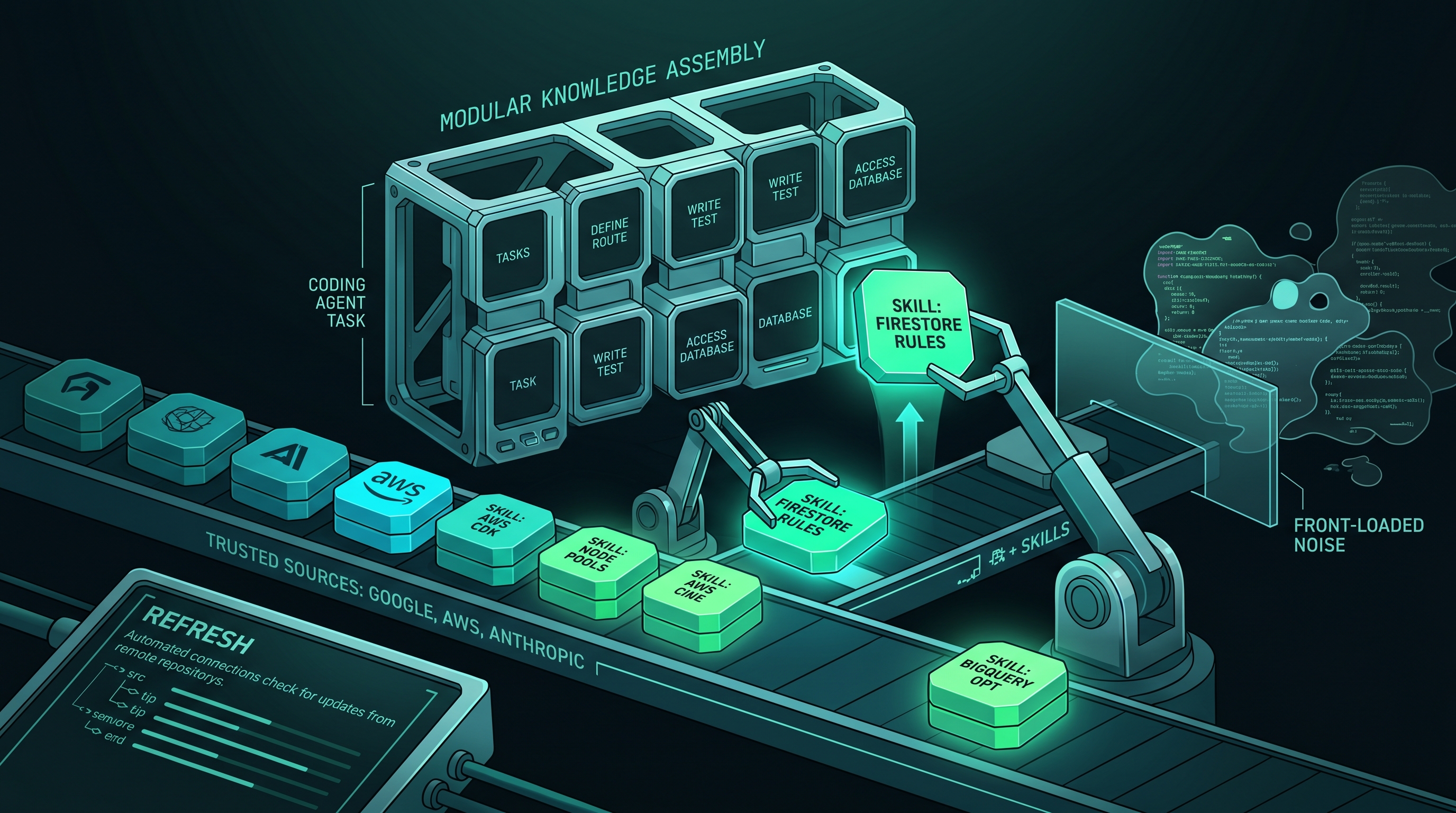
Skills are the unit of knowledge
The mechanism I use for task-specific knowledge is a skill – a structured SKILL.md file that contains the domain context, dispatch patterns, and constraints for a specific capability. A Firestore skill describes how to query collections, what the security rules look like, and how to structure tests. A GKE skill describes the cluster provisioning patterns, how to configure workload identity, and what the common pitfalls are with node pool scaling.
Skills are not general documentation. They’re opinionated, task-shaped context designed to be injected into a coding agent’s prompt at dispatch time. A good skill tells the agent what to do, how to do it in this project, and what not to do. A bad skill is a copy-paste of the official docs – too broad, too generic, and missing the project-specific conventions that actually matter.
The coordinator already matches local skills – the ones I’ve written and stored under ~/.hermes-coder/skills/. The dynamic curator scores them against the task by keyword overlap and injects the top matches. For tasks that stay within my own codebase, this works well. The skills are tailored, current, and trusted.
The gap is external skills. When a task needs domain knowledge I haven’t written a skill for – BigQuery optimization patterns, AWS CDK best practices, Firebase security rules – the coordinator has nothing to inject. It dispatches the task with a good prompt and no specialized knowledge, and the harness has to figure it out from the model’s training data alone. Sometimes that’s fine. Sometimes it produces code that works but doesn’t follow the patterns the cloud provider actually recommends.
Discovery from a curated allowlist
So I built a discovery layer that finds external skills the same way the curator finds local ones – keyword matching against a task description – but searches a curated set of indexes from trusted sources instead of just the local skill directory.
The allowlist is explicit:
- Trusted: Anthropic, Google, Firebase, OpenAI, AWS, Microsoft
- Known: HuggingFace, Model Context Protocol
Each index is a cached snapshot of SKILL.md files from that organization’s public repos. When I run refresh, the system shallow-clones each repo, walks its SKILL.md files, parses the frontmatter (name, description, tags), and caches the index locally. Discovery then searches these cached indexes the same way it searches local skills – keyword overlap between the task summary and the skill’s tags, name, and description – and returns the top candidates ranked by relevance.
This is deliberately simple. No embeddings, no LLM-backed ranking. Keyword overlap is cheap, deterministic, and good enough when the indexes are curated and the entries are well-described. The word “firestore” in the task matches the word “firestore” in the skill. When you’re searching fifty skills from Google, not fifty thousand from the internet, you don’t need a retrieval model.
The key property is that discovery is read-only. It searches cached indexes and returns ranked candidates. No fetches, no writes, no side effects. If the indexes are empty or stale, discovery returns nothing and the dispatch falls through to local skills only. The system fails open to what it already has, never blocks on what it can’t reach.
Trusted sources, not a free-for-all
I ruled out an open marketplace early. When an agent can pull in any skill from any source, you’re one bad index entry away from injecting instructions you didn’t write into your coding engine. A skill is injected context – it shapes what the agent does. A malicious skill doesn’t need to contain executable code to be dangerous; it just needs to tell the agent to do something you wouldn’t approve of.
So the allowlist is the security boundary for discovery. Only sources I’ve explicitly opted into are searched. Adding a new source is a config change, not an automatic expansion.
Beyond the allowlist, sources are tiered by reputation. Trusted sources (Anthropic, Google, AWS, Microsoft, OpenAI) get lighter-touch vetting – a clean audit auto-approves them into the vault. Known sources (HuggingFace, Model Context Protocol) require me to review and explicitly confirm before they’re approved. Unknown sources require the same confirmation plus sandboxed execution for any shipped code.
The full vetting pipeline – the auditor that reads code without executing it, the immutable vault, the sandbox – is its own system and its own post. The point here is that reputation drives how much friction a discovered skill hits before it reaches the harness. Trusted means fewer gates, not no gates.
Injection is per-harness
An approved skill is a SKILL.md file sitting in the vault. To be useful, its contents need to reach the harness at dispatch time. The problem is that each harness accepts context differently, so the injection mechanism adapts to the engine:
Antigravity has no system-prompt flag, so the skill content is prepended to the user prompt. The harness sees it as part of the task description. The skill’s instructions land at the top of the prompt, above the actual task.
Claude Code has the cleanest injection surface. --append-system-prompt injects the skill content as system-level context, separate from the user prompt. The skill gets its own layer in the prompt hierarchy, and --allowedTools can further restrict what tools the harness is allowed to touch.
OpenCode takes file attachments with -f. The skill content gets written to a temp file and attached as context. The harness reads it as supplementary documentation alongside the task prompt.
Same skill, three delivery mechanisms. The coordinator picks the right one based on which harness is active – the same pattern as the dispatch wrappers from the last post.
What this looks like in practice
Without discovery, a dispatch looks like this: the coordinator builds a prompt (“add a Firestore listener for the users collection, following the patterns in src/db/”), wraps it in the active harness, and sends it. The harness has the task and the role. It doesn’t have the knowledge – the Firestore client patterns, the security rule conventions, the test structure for database modules.
With discovery, the coordinator first asks: are there skills that match this task? The discovery step finds a Google-published Firestore skill in the cached index, checks that it’s approved in the vault, and injects its contents into the harness alongside the prompt. Now the harness has the task, the role, and the domain knowledge. It knows the recommended patterns for Firestore listeners, the security rules to check, and how to structure the tests – not because the model was trained on them, but because the coordinator loaded exactly that context for exactly this task.
The difference matters most for tasks where the model’s training data is stale, incomplete, or generic. Cloud SDKs change often enough that a model trained six months ago may suggest deprecated patterns. A skill from the cloud provider’s own repo carries the current recommendations. The agent gets the right answer because it was given the right context, not because it guessed well.
The refresh cycle
Indexes go stale. Google adds a Cloud Run skill; Anthropic deprecates one that no longer applies. If the cached snapshot never updates, discovery surfaces outdated candidates or misses new ones.
The refresh command handles this: skill_discovery.py refresh --confirm re-pulls every wired repo, walks its SKILL.md files, and atomically rewrites the cache. It also checks whether any vaulted skills have changed upstream – if a hash doesn’t match, it flags the skill for re-vetting.
The refresh is documented, not automatic. The config has a cron expression for it, but it doesn’t run on its own. I run it manually when I want to update the indexes. An automated refresh that runs while I’m not watching would silently re-pull indexes and potentially change what gets injected into dispatches. I’d rather update when I’m paying attention.
Network tolerance is built in. If a clone fails, the refresh keeps the stale cache and reports the degradation. It doesn’t throw away the last good snapshot because the current pull didn’t work.
What this doesn’t cover
This system discovers SKILL.md files – structured documentation injected as context. It does not discover MCP servers, which are a different injection surface entirely: you’re spawning a process and giving it tool-call access, not injecting a text file. MCP discovery is a documented follow-on with its own allowlist and vetting rules.
The keyword scoring is also deliberately unsophisticated. It works because the curated indexes are small and well-described. If the index grows to thousands of entries, keyword overlap won’t be enough – you’d want embeddings or a model-backed ranker. That’s a problem I’ll solve when the index needs it.
What’s next
Discovery solves what knowledge a task needs. But pulling in external skills – especially ones that ship executable code – raises a harder question: how do you vet code you’ve never seen without running it? How do you let it execute without trusting it?
The next post is about the security pipeline underneath all of this: the auditor that reads code without executing it, the immutable vault that locks down approved copies, and the sandbox that caps the blast radius when something does run. Every discovered skill passes through that pipeline before it reaches the harness. This post described what gets injected; the next one describes how it earns that trust.
The Hermes Agent series
- Part 1: I Built an Always-On AI Coding Agent That Plans, Codes, and Reviews Its Own Work
- Part 2: One Coordinator, Swappable Coding Engines
- Part 3: Dynamic Tool Discovery and Injection (this post)
- Part 4: Running Untrusted Tools Safely
- Part 5: GitHub Issues as the Agent’s Backlog
- Part 6: The Autonomy Ladder
- Part 7: How the Agent Learns From Its Mistakes