Part 7: How the Agent Learns From Its Mistakes
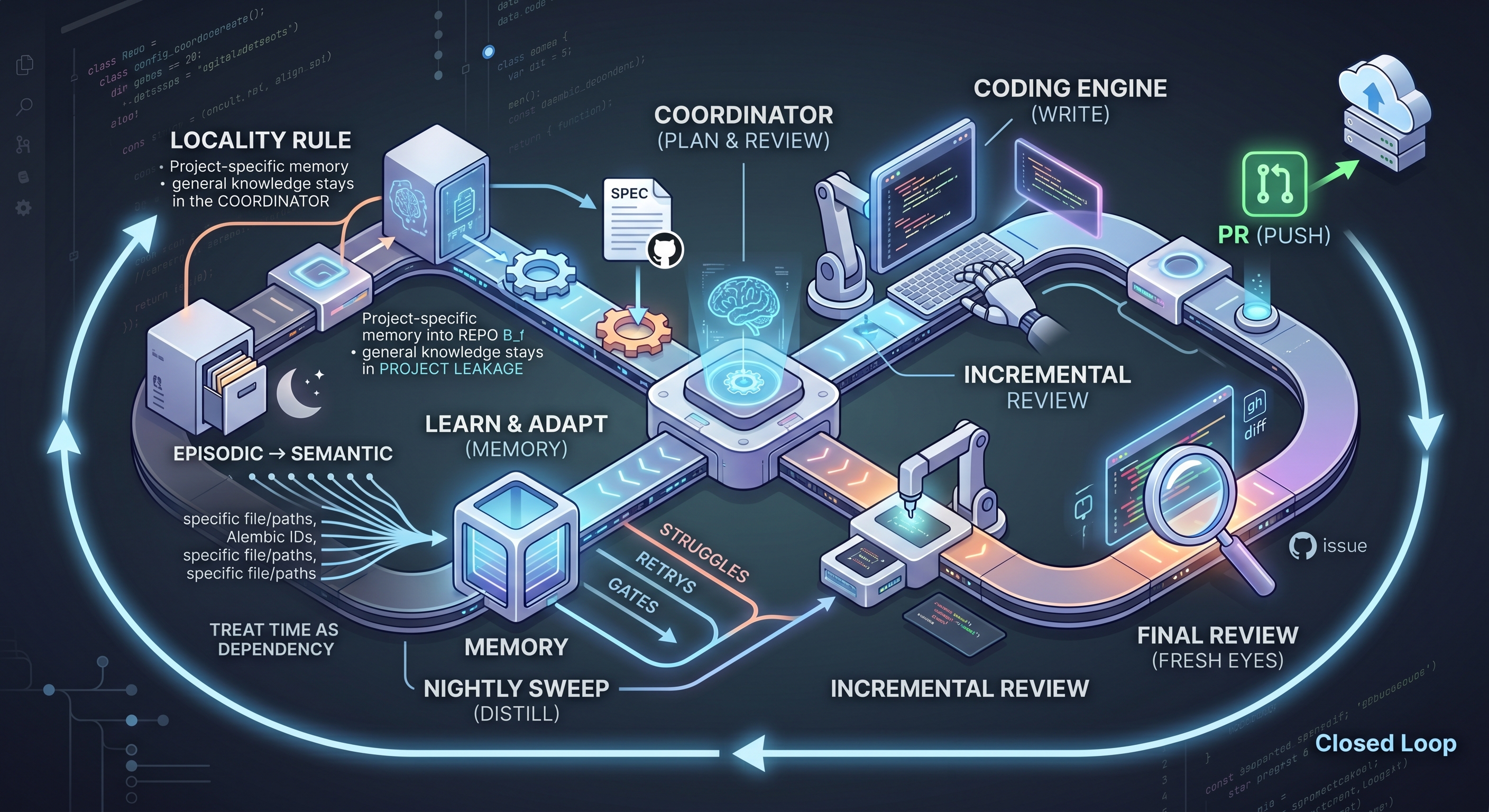
In the first post of this series I described the split at the heart of my setup: a coordinator that plans and reviews but never writes code, and a coding engine that writes code but never plans. Every task the engine completes gets reviewed twice before the coordinator moves on: once against the spec, once for code quality.
That sounds thorough. It has a hole in it. And patching the hole pulled a thread that ran further than I expected: the patch needed memory to be worth anything, the memory expanded and got too specific, and cleaning that up exposed knowledge sitting in places it should never have been. By the end, the system had grown a more mature and focused closed loop. This post walks through it: the catch, the learning, and the part where memory finally learned where it belongs.
Catch: fresh eyes before every push
The coordinating agent breaks work down into smaller tasks and dispatches them to specialized agents (with a specific role, task, and knowledge). But per-task review is incremental. The reviewer sees one task’s output at a time, in the same conversation that planned it. A finished feature might span five tasks, two auto-heal retries, and a refactor the plan never mentioned, yet nobody ever reads the whole change set against the whole spec. The coordinator reviewed each tree. Nothing reviewed the forest. And the reviewer helped write what it’s reviewing, which is the worst seat in the house for spotting problems.
Human teams solved this a long time ago: before you merge, someone who didn’t write the code reads the diff. So I built that.
Right before the coordinator pushes and opens a PR, it dispatches one more coding-engine task. This one gets three inputs:
- The full diff. Everything on the branch versus the base, committed and uncommitted. The reviewer pulls it itself with
git diff. - The spec. The GitHub issues being resolved, fetched live with
gh issue view, or the written spec for work that isn’t issue-tracked. - The proposed PR message. What the coordinator is about to claim this change does.
The dispatch is a fresh process with no memory of the conversation that produced the code. It didn’t write any of this, didn’t watch it being written, and has no investment in it being fine. That’s the entire value. The prompt tells it to trace logic end to end across all execution paths, treat the issues’ “Known Gotchas” as strict requirements, and check that the PR message actually describes the diff.
Then comes the part that makes it more than a linter: the reviewer has edit rights. With Read,Edit,Write,Bash it can fix what it finds, run the tests, and confirm the tree is green before handing back. Think of this as the senior engineer reviewing and fixing the work before it is pushed.
Giving a reviewer write access is asking for scope creep, so the prompt draws hard lines. Minimal, targeted fixes for real problems only. No refactoring, no new features, no style opinions applied as edits. Anything non-blocking that it would merely prefer gets recorded as a residual risk instead of changed. And if it finds a blocking defect it can’t fix safely within those lines, it doesn’t paper over it. It returns a blocked verdict, and the coordinator stops. No push, no PR. The blocker goes to me to handle.
The gate doesn’t get its own authority knob, because the last thing this system needs is a second permission model to reason about. The reviewer never touches the remote at all. It reviews and edits locally, and the coordinator drives delivery through the same autonomy ladder as always: gated previews the commands and waits for my confirmation, push-draft opens a draft PR unattended, full opens a real one. If the reviewer made fixes, those get committed first, through the same commit tooling and the same hygiene checks, and the PR body gains a section the reviewer wrote: Final review fixes, a plain list of what it changed at the last minute and why. A review step that silently patches things is worse than no review step, because you stop knowing where your defects come from.
The gate doesn’t run on everything. A one-line fix for a single small issue doesn’t need a second full review; the per-task review already covered it, and the gate costs real tokens and minutes. The rule I landed on: bypass only when the delivery resolves a single issue sized XS or S. Multiple issues in one branch, at any size, always get the gate, because cross-issue interactions are precisely what per-task review can’t see. And when the engine is unreachable, the gate degrades instead of deadlocking: the coordinator falls back to its own reviewer lens, notes the skip out loud, and proceeds with appropriate suspicion.
The gate is new, so I won’t invent victories for it. But I built it for the misses I kept seeing in multi-issue branches. Two changes that are each correct alone and wrong together, like one task adding a migration while another queries the old schema. A PR message that describes the plan instead of the code, because the plan changed partway through. A “Known Gotcha” that one task honored and a later task never saw. No single task contains any of these problems, so per-task review can’t catch them. A reviewer reading the whole diff against the whole spec can’t miss them.
And the reviewer’s report doesn’t just go into the PR body. “What I fixed and why” is a description of what the upstream process missed, which makes it training data for the process itself. Using it that way requires the one thing my coding engines don’t have: memory.
Learn: lessons come from struggle
The coding engines in my setup have no memory. Every dispatch is a fresh process with a self-contained prompt: here are the files, here is the change, here is how to verify. That statelessness is a feature (it’s what makes engines swappable and dispatches reproducible), but it has an obvious cost. The engine that spent forty minutes last Tuesday discovering that a flaky test was actually a timezone bug starts from zero on Wednesday. Whatever was learned, evaporated.
The coordinator is long-lived, so the fix seems easy: have it remember. But “remember everything” turns out to be almost as useless as “remember nothing,” and the interesting engineering is in the middle.
Not every completed task teaches you something. Most work goes fine, and recording “implemented the endpoint, tests passed” five hundred times is noise. So the retrospective tool self-gates: it only captures when there was a real struggle. Three sources qualify:
- Auto-heal retries. When the test-fixing loop needed more than one attempt, or escalated entirely, the heal report carries the failure trail.
- Debugger sessions. A systematic debugging run produces a journal — root cause file, data flow, fix outcome. If there’s a traced root cause, there’s a lesson.
- Final reviews. Whatever the fresh-eyes reviewer fixed or flagged at the delivery boundary is, by definition, something the upstream process missed.
In each case the evidence goes through one LLM pass that distills it to two sentences: what was actually wrong, and what to do differently next time. That gets stored as a small JSON file in the repo’s own lesson directory, per project, because a lesson about one codebase’s test fixtures is rarely a lesson about another’s. If the harness is down, a rules-only fallback still stores a cruder lesson. Capturing something beats capturing nothing.
Storage is worthless if nothing reads it. Before every dispatch, the coordinator runs the task description against the lesson store: plain keyword overlap, scored and thresholded, capped at the three best matches. Those get appended to the dispatch prompt as a short block: lessons from prior work in this repo.
The cap matters more than the matching. The temptation is to inject everything vaguely related, and every line you add to a prompt competes with the lines that describe the actual task. Three relevant sentences change behavior. Thirty drown it.
This loop (struggle, capture, inject) worked from the start. Then it started to rot.
Consolidate: the nightly sweep
A few weeks in, I read through what the system had remembered. The lessons were good. They were also hyper-specific: exact file paths, an Alembic revision ID, the name of one project’s test database, a particular mock that had leaked in one particular suite.
Specific memories age badly. The file gets renamed and the lesson points at nothing. Worse, they generalize badly: the timezone lesson learned in tests/auth/test_token.py:42 is true everywhere, but keyword matching will only ever surface it for auth work. And they accumulate without bound, which means injection slots fill with stale specifics while the durable principle underneath never gets written down.
Humans have a mechanism for this. You don’t permanently store every detail of every day. Sleep does something ruthless and useful: it replays experience, keeps the structure, and lets the specifics fade. Episodic memory in, semantic memory out. You forget the parking spot; you keep the lesson about that neighborhood.
I am not going to claim my agent dreams. But I built the same shape, and it runs at night. Every night, a few minutes before the system backs itself up, a sweep runs over each repo’s lesson store:
- Cluster. Lessons are grouped by tag overlap (Jaccard similarity on their keyword sets). Three lessons about token refresh, JWT expiry, and retry backoff in the auth flow land in one cluster.
- Merge. Each cluster goes through one LLM pass with strict instructions: produce one general lesson, principle-level, stripping incidental file paths and revision IDs unless they’re essential to the point.
- Archive, don’t delete. The original specific lessons move to an archive directory. Generalization is lossy on purpose, but lossy with a paper trail: if a merged lesson ever looks wrong, the episodes that produced it are still there.
- Cap. The store is bounded. Past the cap, the oldest lessons age out into the archive. Memory that grows forever isn’t memory, it’s a landfill.
Here’s the run that convinced me, from validating the sweep. I seeded three lessons of exactly the shape the system captures: a flaky auth test where token refresh raced a clock mock; a JWT expiry bug from comparing naive and aware datetimes; a refresh endpoint retrying without backoff. The sweep clustered all three and merged them into one sentence:
When implementing or testing token lifecycles, treat time as a first-class dependency: use consistent timezone-aware datetimes, inject/control clocks in tests, and apply backoff to time-sensitive retries.
None of the three original lessons said that. All three are instances of it. That sentence will match — and deserve to match — far more future tasks than any of the specifics would have.
Why nightly instead of on every capture? A boring reason: that’s when nothing else is running, and the backup that follows preserves both the new general lessons and the freshly archived episodes in one snapshot. The schedule wasn’t chosen for the metaphor. The metaphor was just sitting there once the schedule existed.
Reading those over-specific lessons also surfaced a second problem, and this one wasn’t about how the system remembers. It was about where.
Place: project memory belongs in the project
I found it while reviewing a snapshot of the coordinator itself. The coordinator publishes a sanitized copy of itself (the scripts, the curated skills, the workflow rules) to a public reference repo, so other people can build the same setup. The publisher has a scrub gate that fail-closed aborts on secrets, real usernames, machine paths. In a recent snapshot I found something the gate wasn’t looking for: the name of one of my private projects. Then its test database name. Then a reference doc describing another project’s schema quirks, and a rule about which upstream repo my fork must never push to.
Nothing catastrophic. No secrets, no tokens. But my general-purpose coordinator had quietly become a directory of my private work, and it was publishing notes about it.
Nobody designs this. It accumulates, because an agent that learns will write what it learns to the most convenient place, and the most convenient place is its own home directory. The coordinator works across every repo on my machine. When a session in one project surfaces something worth keeping (this app uses SQLite for tests and Postgres in prod, this fork must never PR upstream, this codebase had a subtle constraint-naming pitfall), the learning lands in the coordinator’s own memory, or gets written into one of its skills as a “reference” doc. Each individual write is reasonable. The sum is two real problems:
Context crowding. The coordinator’s memory loads into every session. Facts about project A are pure noise while working on project B, and they compete for the same context budget as the instructions that matter. The more projects, the worse the ratio gets.
Leakage. The coordinator’s home is exactly what the public snapshot is built from. Project knowledge stored there is project knowledge on a conveyor belt toward a public repo, with only pattern-matching between it and the internet.
Both problems have the same root: the knowledge was stored in the wrong place. The fix isn’t better scrubbing. It’s locality. The principle is one sentence: if a learning names a project, it belongs in that project. Everything else follows from asking “who needs this, and when?”
| The learning | Where it lives |
|---|---|
| Cross-project workflow, tooling, environment facts | Coordinator memory — short and general |
| A reusable engineering pattern | A skill — genericized, placeholder names only |
| One project’s stack, schema, services, fork rules | That repo’s AGENTS.md, under a “Project memory” section |
| Research docs, audits, case studies of one project | That repo’s docs/hermes/, linked from its AGENTS.md |
| Struggle-derived fix lessons | That repo’s lesson store |
The reason AGENTS.md is the anchor: it’s loaded automatically when an agent works in that repo, by my coordinator and by other coding agents that honor the convention. So project memory surfaces exactly when it’s relevant and never when it isn’t. The context-crowding problem doesn’t get managed; it disappears, because the memory is only in context when you’re standing in the project it describes. It also means the memory travels with the repo. Clone the project on a new machine, and the agent context comes along; it’s just files in git. Project knowledge stored in one agent’s home directory is knowledge with a single point of failure.
Applying the rules to the existing mess was a one-time migration. Seven reference docs moved out of the coordinator’s skill library into their projects’ docs/hermes/ folders. Each affected repo got an AGENTS.md section distilling what the coordinator had memorized about it. The coordinator’s memory entries about individual projects were deleted and replaced with a single pointer rule: project facts live in the project; check its AGENTS.md when you start work there.
The interesting part was the in-between category, docs that were mostly reusable patterns with project residue baked in: a real database name in a CI example, a real namespace in a Kubernetes troubleshooting guide, domain types from one app’s frontend in a TypeScript hardening doc. Those got scrubbed in place: the lesson stays in the skill library, the identifiers become placeholders. The general pattern was always the valuable part; the residue was just what it happened to be learned from.
The relocated files get committed in each project on its current branch, locally. The agent never pushes them; deciding what reaches a remote stays a human action, same as every other rule in this system.
A one-time cleanup decays unless something maintains it. Three mechanisms now hold the line:
Write-time rules. The coordinator’s standing instructions now state the placement table outright, with an invariant: no project-specific facts in coordinator memory or skill references; they go to the repo. The cheapest enforcement is the agent not making the mess.
The nightly sweep. The same pre-backup sweep that consolidates lessons also audits the coordinator’s memory. Each entry gets classified: genuinely general, keep; general but bloated, condense; about one project, relocate — appended to that repo’s AGENTS.md with a local commit, then removed from coordinator memory. The pre-edit files are backed up first, and the sweep’s digest tells me what moved. Agents drift back toward convenient writes; the sweep drifts them back out, daily.
The leak gate. The snapshot publisher’s scrub gate now includes my private project identifiers alongside the secrets patterns. Any hit anywhere in the publishable tree aborts the publish entirely. I tested it by planting a database name in a skill and watching the publish refuse to run. Defense in depth: hygiene keeps the names out, and if hygiene ever slips, the gate means the failure mode is “tonight’s snapshot didn’t publish,” not “my project details are public.”
There are some trade-offs
Almost every moving part here is an LLM judgment call, and LLM judgment calls vary. Some of the sweep’s merges will be blander than the episodes they replace; the archive is the hedge, not a guarantee. The clustering threshold took tuning; my first cut was too strict and clustered nothing, because real lessons share fewer keywords than you’d guess. The memory classifier’s question, “is this entry about one project or about all of them?”, is usually obvious and occasionally not, and a wrong relocation moves a useful general fact somewhere only one project sees it. And all of it runs unattended, which means a bad judgment propagates until I notice it in the digest.
The mitigations are boring and adequate: propose-only mode for review, backups before every applied change, and a digest log that tells me what moved. The leak gate has the opposite character (dumb pattern matching, zero judgment), which is exactly what you want from a last line of defense.
There’s also a cost I accepted knowingly: project memory in AGENTS.md is visible to anyone with repo access, including every agent and human collaborator. That’s the point, but it means the memory has to be written as documentation, not as a private scratchpad. I consider that a feature disguised as a constraint.
I accept the rest too, because the alternative I actually lived with, an unbounded pile of expired specifics stored in the wrong brain, was strictly worse.
The loop, complete
The final review gate catches what incremental review misses. The retrospective learns from every catch and struggle, and applies it by injecting lessons into future work. The nightly sweep consolidates specifics into principles, and keeps every memory where it belongs: general knowledge in the coordinator, project knowledge in the project, and private names out of public snapshots.
None of these pieces is sophisticated on its own. A diff review, a JSON file of lessons, a classifier, and a grep that refuses to publish. The compounding comes from them running every day without being asked.
The Hermes Agent series
- Part 1: I Built an Always-On AI Coding Agent That Plans, Codes, and Reviews Its Own Work
- Part 2: One Coordinator, Swappable Coding Engines
- Part 3: Dynamic Tool Discovery and Injection
- Part 4: Running Untrusted Tools Safely
- Part 5: GitHub Issues as the Agent’s Backlog
- Part 6: The Autonomy Ladder
- Part 7: How the Agent Learns From Its Mistakes (this post)